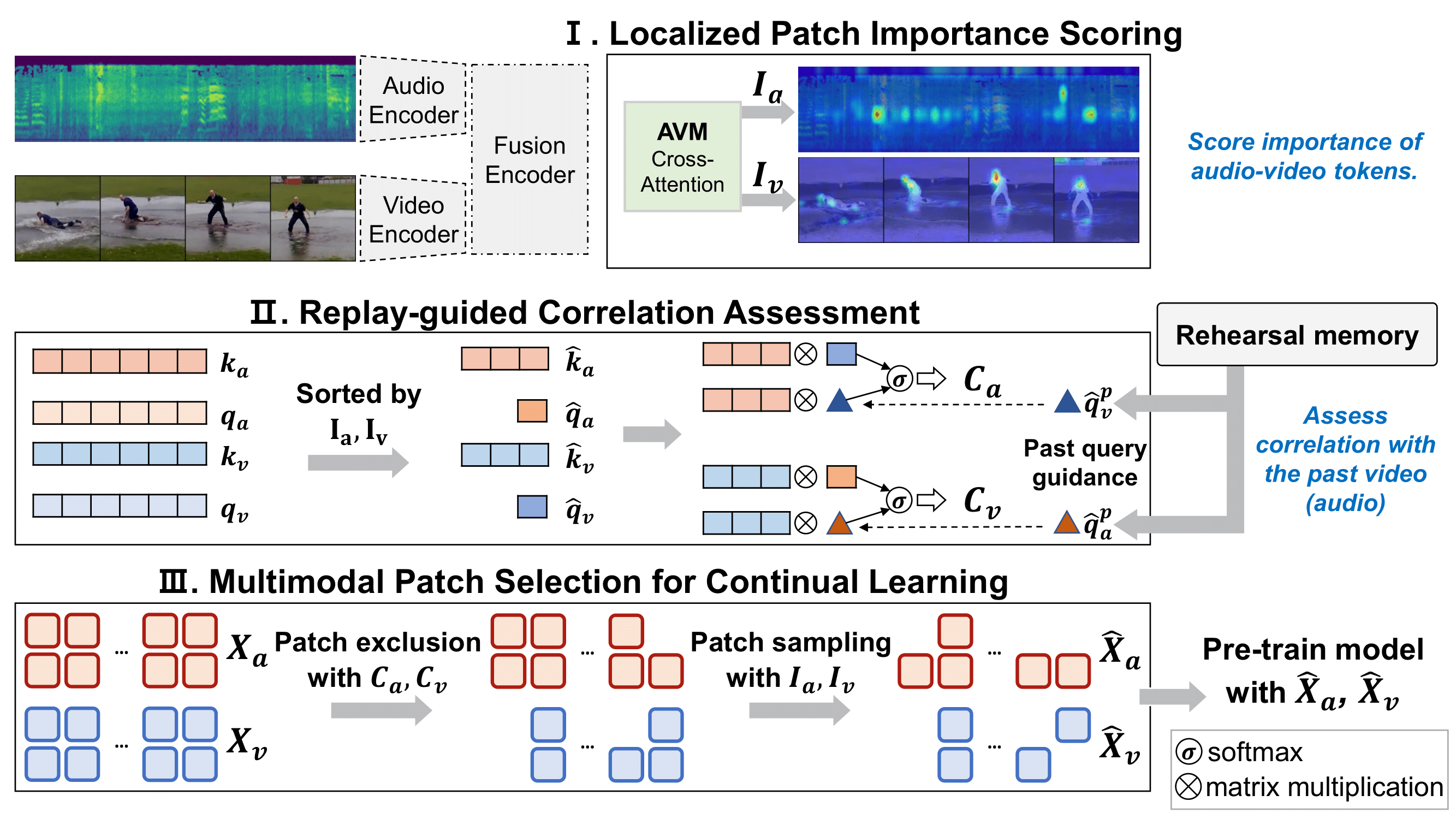
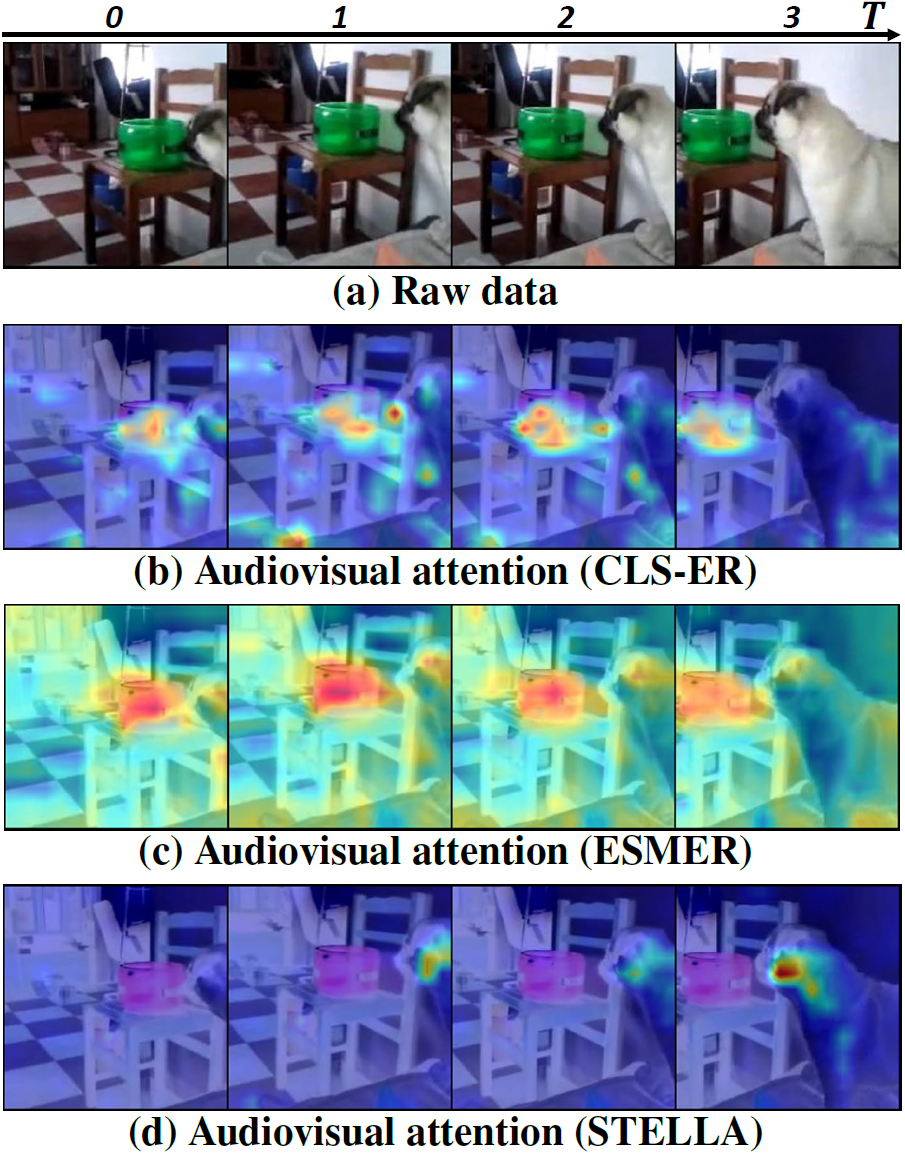
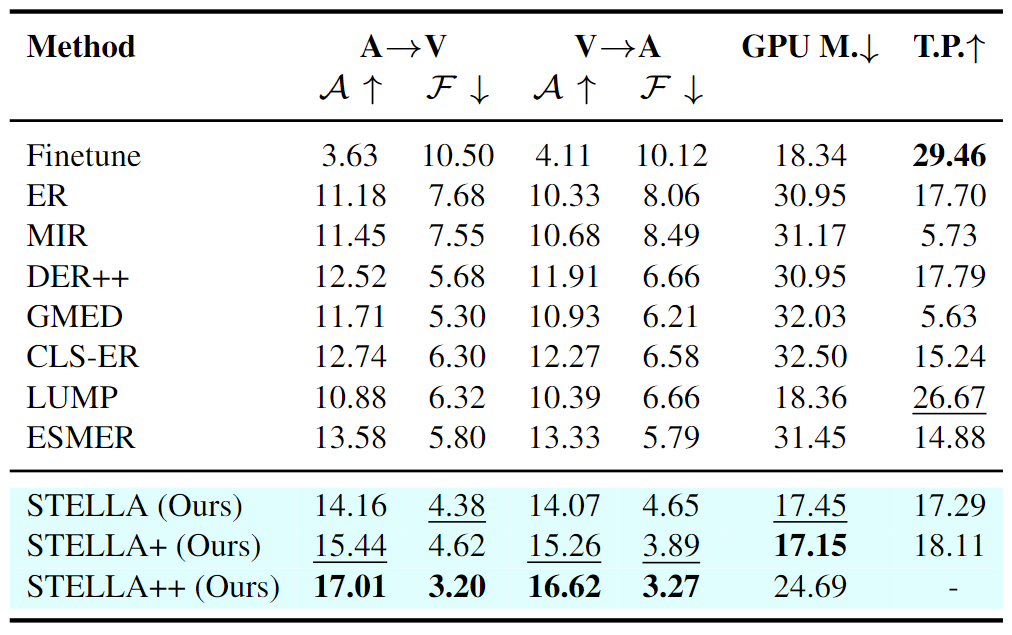
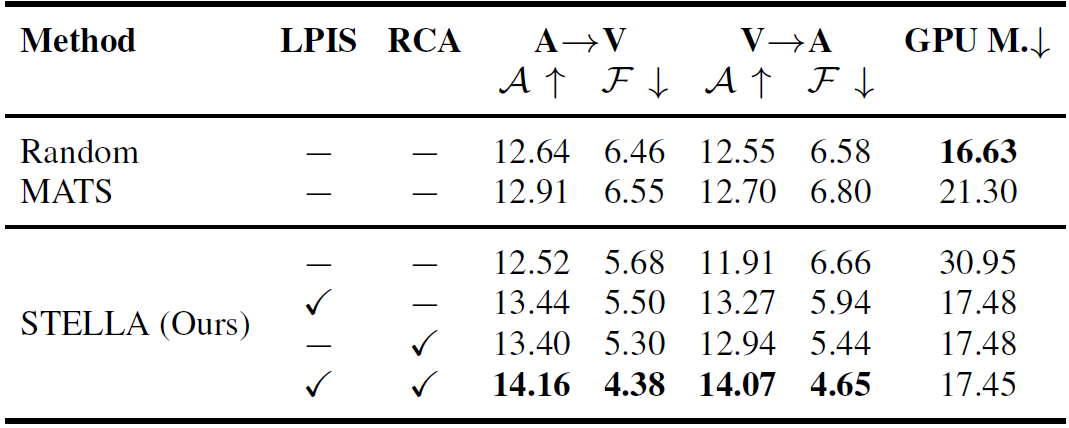
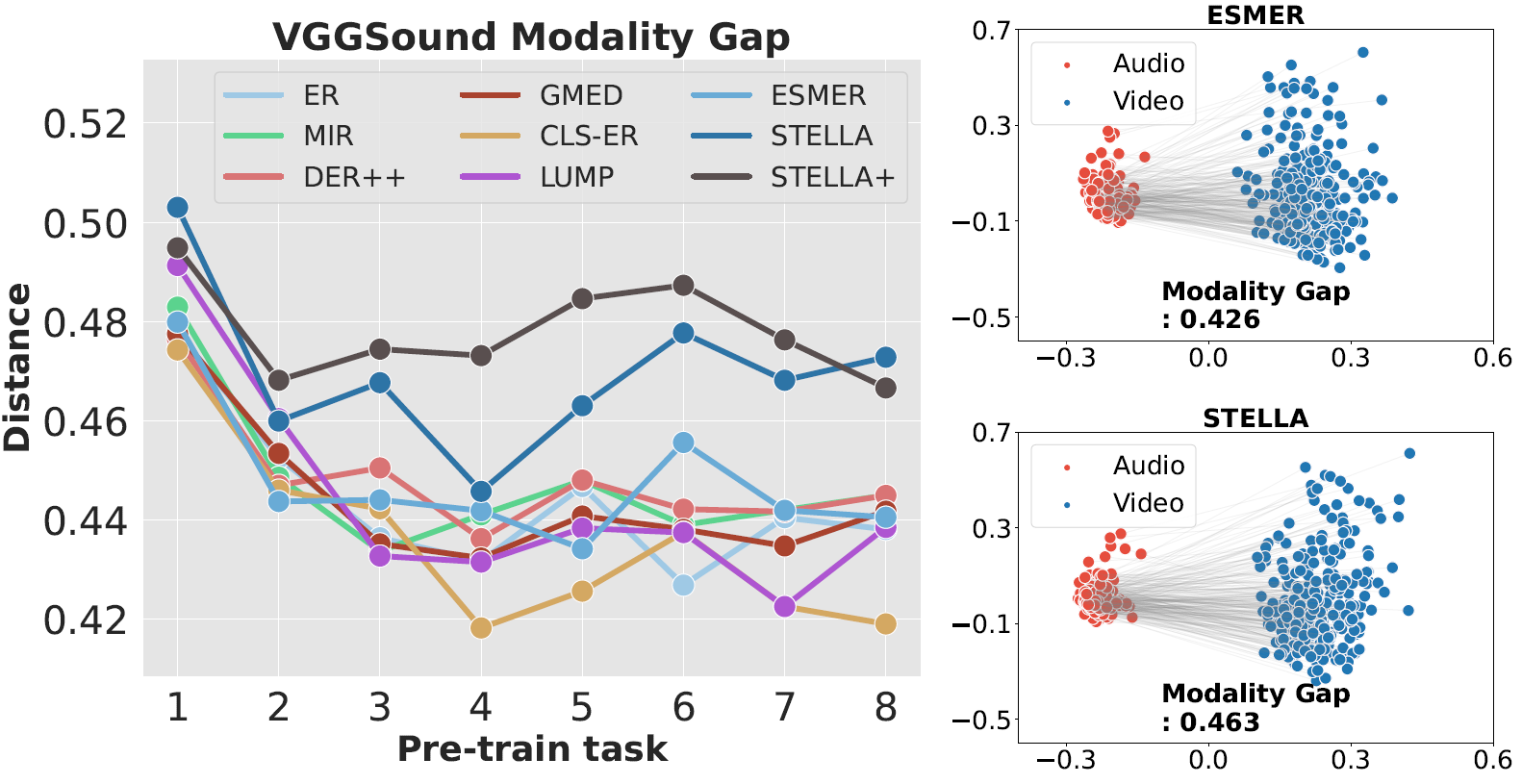
Motivation
Emerging new audio-video semantics
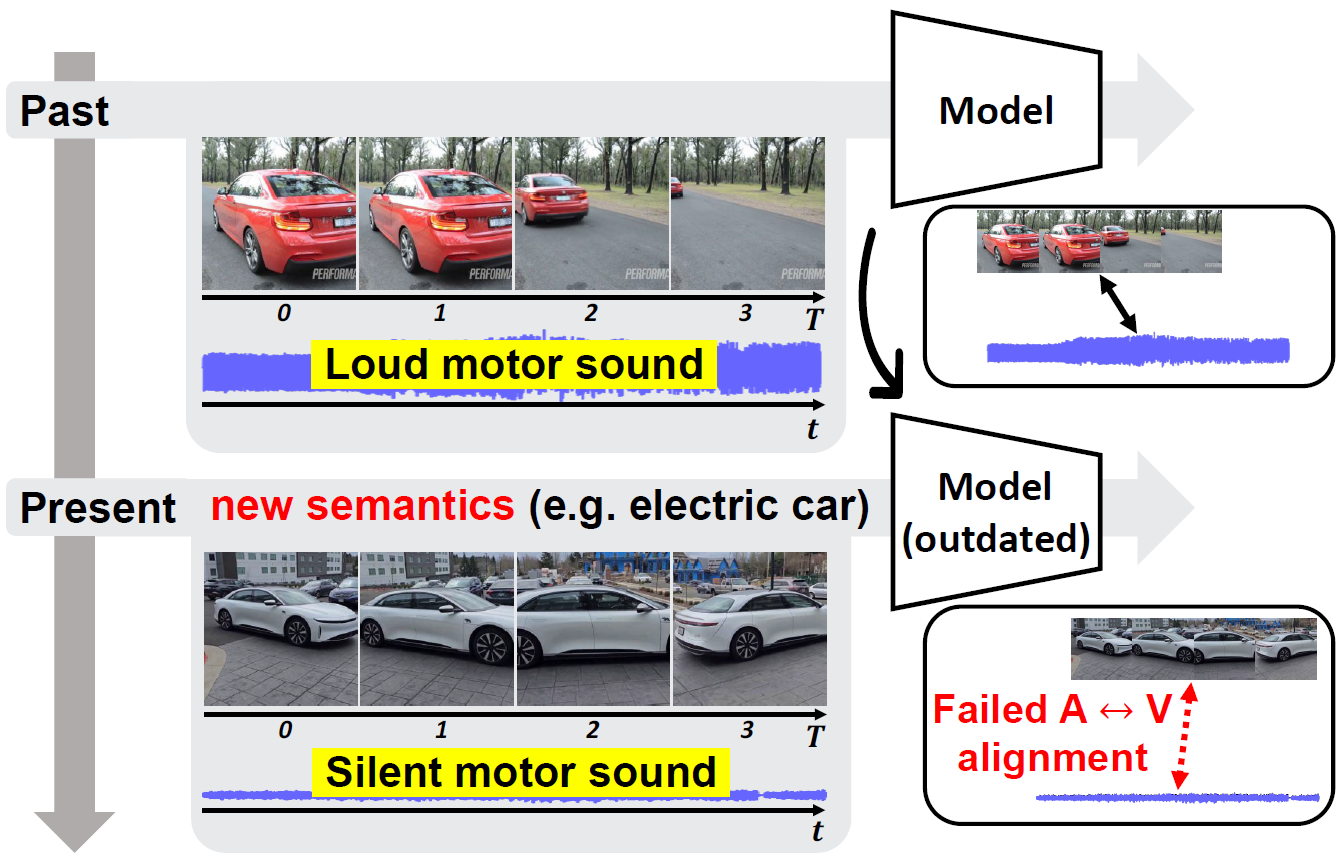
Outdated pre-trained audio-video models struggle with understanding emerging new audio-video semantics.
Challenges in continual audio-video learning

Learning audio-video data with continuously changing semantic categories is a nontrivial problem due to two critical challenges:
1) sparse spatio-temporal correlation between audio-video pairs, and 2) multimodal correlation overwriting.
Challenge of multimodal correlation overwriting
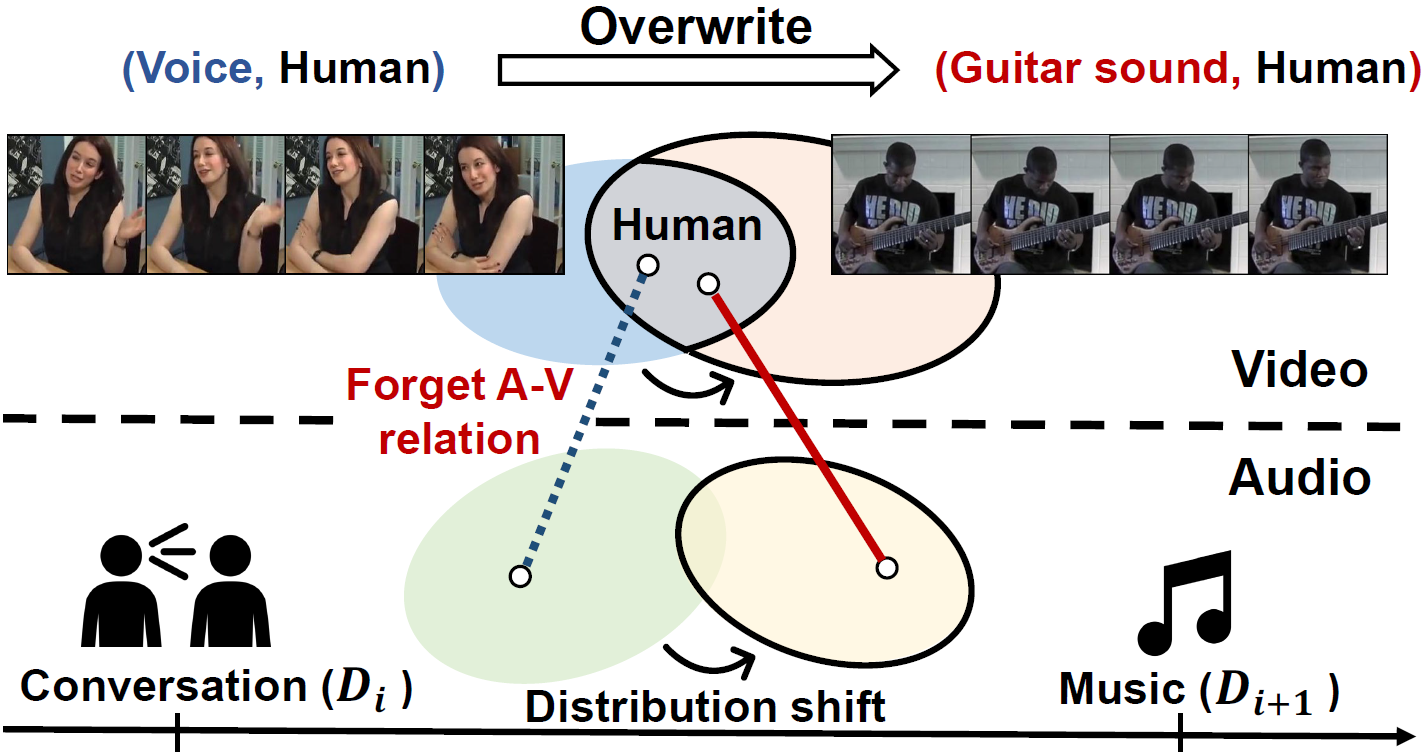
During continual pre-training, the model can encounter new semantics sharing key visual objects, making the model overwrite the previously learned audio information, resulting in forgetting.